Use this file to discover all available pages before exploring further.
Build an AI assistant that remembers user preferences, past conversations, and upcoming commitments. This guide shows you how to integrate EverOS into a personal assistant workflow.
Install the EverOS Python SDK and initialize the client. No scene or conversation-meta configuration is needed in v1 — just start adding memories directly.
pip install everos
from everos import EverOSimport timeclient = EverOS()memories = client.v1.memories
Here’s a complete implementation that ties everything together:
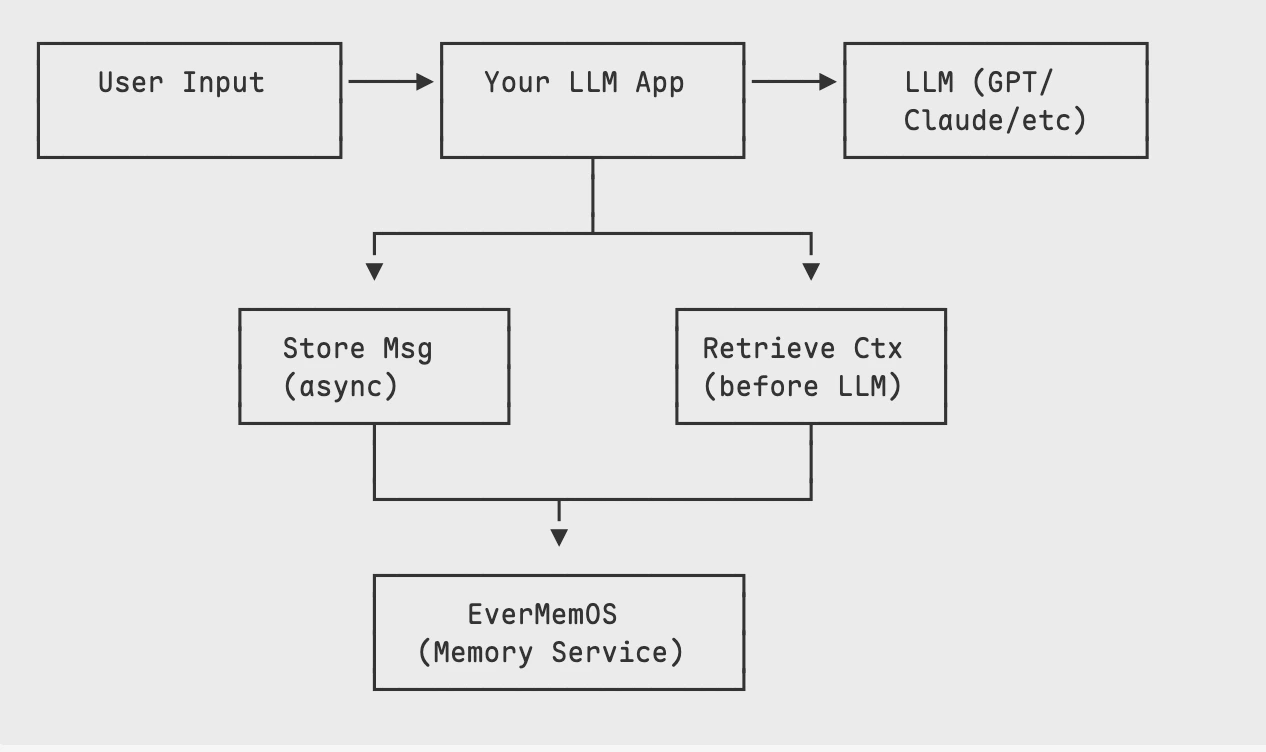
from everos import EverOSimport timeclient = EverOS()memories = client.v1.memoriesclass PersonalAssistant: def __init__(self, user_id: str): self.user_id = user_id def _store_message(self, content: str, role: str = "user"): """Store a message in EverOS.""" memories.add( user_id=self.user_id, messages=[ { "role": role, "timestamp": int(time.time() * 1000), "content": content, } ], ) def _get_context(self, query: str) -> str: """Retrieve relevant memory context.""" result = memories.search( filters={"user_id": self.user_id}, query=query, method="hybrid", memory_types=["profile", "episodic_memory"], top_k=5, ) found = result.get("result", {}).get("memories", []) if not found: return "No relevant memories found." parts = [] for mem in found: mem_type = mem.get("memory_type", "").replace("_", " ").title() content = mem.get("memory_content", "") parts.append(f"[{mem_type}] {content}") return "\n".join(parts) def _generate_response(self, user_message: str, context: str) -> str: """Generate response using your LLM of choice.""" # Replace this with your actual LLM call (OpenAI, Anthropic, etc.) prompt = f"""You are a helpful personal assistant. Use the following context about the user to personalize your response.MEMORY CONTEXT:{context}USER MESSAGE:{user_message}Respond naturally, incorporating relevant context when appropriate. Don't explicitly mention that you're using memory unless asked.""" # Example: OpenAI call (replace with your LLM) # response = openai.chat.completions.create( # model="gpt-4", # messages=[{"role": "user", "content": prompt}] # ) # return response.choices[0].message.content # Placeholder for demo return f"[LLM would respond here with context: {context[:100]}...]" def chat(self, user_message: str) -> str: """Main chat method - store, retrieve, generate, store.""" # 1. Store user message self._store_message(user_message, role="user") # 2. Retrieve relevant context context = self._get_context(user_message) # 3. Generate response with context response = self._generate_response(user_message, context) # 4. Store assistant response self._store_message(response, role="assistant") return response# Usageassistant = PersonalAssistant("user_alice")# Simulate conversationprint(assistant.chat("I prefer meetings in the morning, before 10am."))print(assistant.chat("What time works best for our call tomorrow?"))# The second response will use memory of the preference!
After a few conversations, your assistant can leverage stored preferences:
# Earlier conversation (already stored)# User: "I'm vegetarian and allergic to nuts"# User: "I love Italian food"# Later conversationuser_message = "Can you suggest a restaurant for dinner?"context = assistant._get_context(user_message)# Context includes:# [Profile] User is vegetarian# [Profile] User has nut allergy# [Profile] User enjoys Italian cuisine# LLM generates: "How about that new Italian place downtown?# They have great vegetarian options and I checked - they're# nut-free friendly!"
Limit retrieved memories to avoid overwhelming your LLM context window.
# Good: Limit to most relevanttop_k=5# Better: Truncate if neededcontext = context[:2000] # Limit to ~500 tokens
Choose the Right Search Method
EverOS v1 supports multiple search methods. Pick the one that fits your use case.
# Semantic similarity -- best for intent matchingmethod="vector"# Hybrid (keyword + vector) -- good general-purpose defaultmethod="hybrid"# Agentic -- lets the model decide what to retrievemethod="agentic"
Filter by Memory Type
Request only the memory types you need to keep results focused.
# User facts and preferencesmemory_types=["profile"]# Past conversation summariesmemory_types=["episodic_memory"]# Bothmemory_types=["profile", "episodic_memory"]